

The only AI-enabled decision intelligence platform that mimics human decision-making in the SOC, regardless of specific tools and workflows.
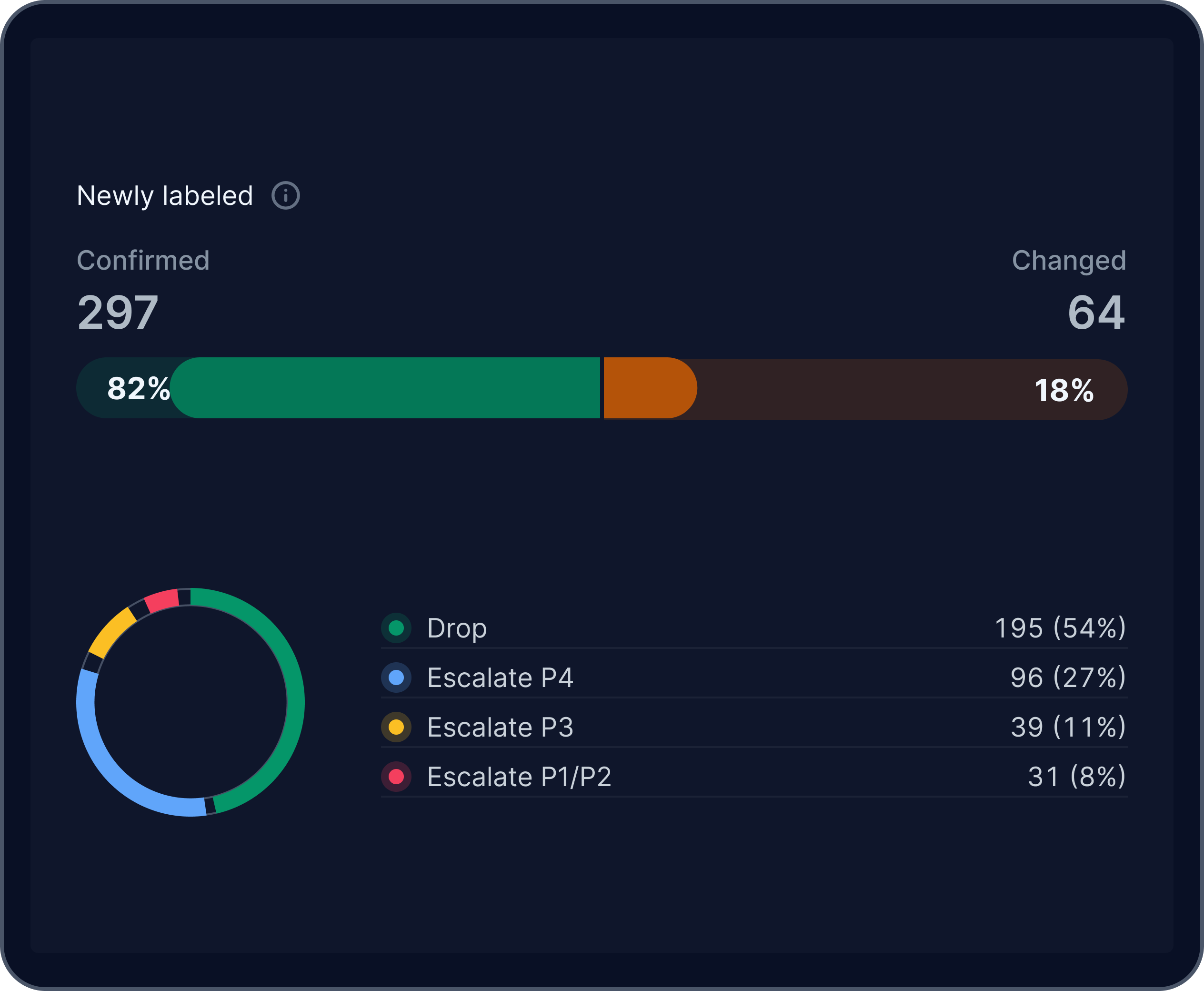

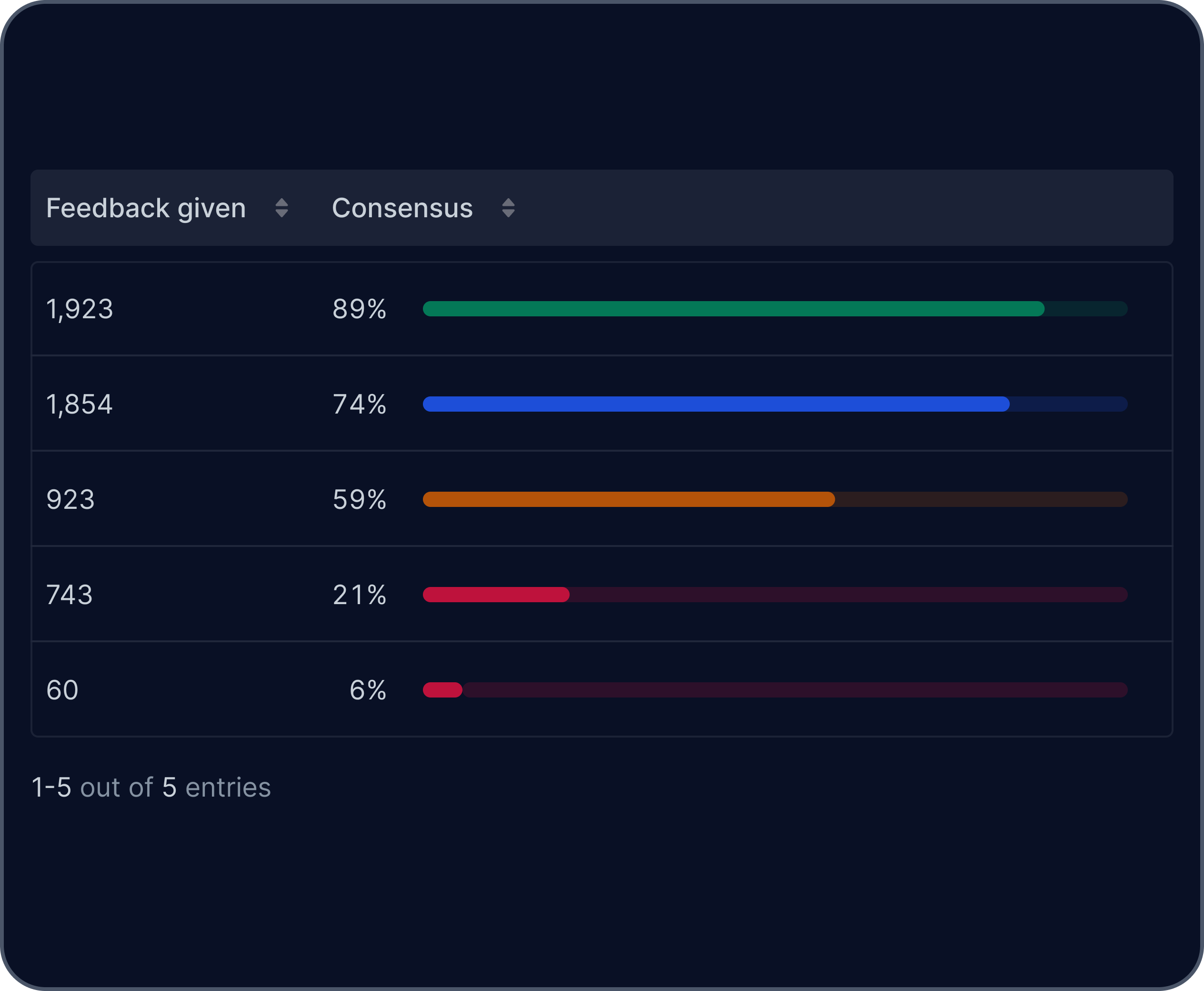
Arcanna.ai enhances your team's capability, streamlines threat handling and mitigates risk associated with alert fatigue.
Quick decisions hinge on context, but analysts lack time and resources. Arcanna.ai overcomes these limitations, emulating the decision making process.
